Hash Text
This section provides a comprehensive description of the Hash Text Rule.
For a summary of the rule and its compatibility with Privitar jobs and execution environments, see  Masking Rule Types.
Masking Rule Types.
Data Types
The supported data types for this rule are:
Text
Description
The original value is completely replaced by a generated SHA256 salted hash with a pepper secret. By default, the hash will be a base 64 string. However, you can create a custom hash output by specifying a regular expression with the rule.
The rule does not utilize a Token Vault, so there is no support for Unmasking of any output value. As the input value is hashed, there is no way to return to the input value; the rule output is irreversible.
Consistency in tokenization is achieved by the hashing function. Effectively, the function will always return the same output value for the same input value within a given PDD for a specific rule.
Note
This rule can only be used in a Job that has a KMS configured in the Privitar Environment. The only KMS that is currently supported is the AWS Secrets Manager. For more information, see Key Management Environment Configuration.
Masking Behavior
The options are described in the following table and assume that the original value is not null:
Option | Description |
|---|---|
default | If you do not specify a regular expression, the default output is a (hashed) base 64 string. |
Regular expression | The pattern that the generated text should match. Using a regular expression with the rule ensures that it is possible to add a Watermark to the dataset. Watermarking is not available if the default hashing function is used. For more information, see Watermarking a Dataset. For more information about the regular expression syntax supported in Privitar, see Regular Expression Syntax. (Click on the RegExp class in the Class Summary table.) |
Examples
The following diagram illustrates the output behavior of the rule. The first two examples show how the same input value produces the same output value. The final example shows how the output value can be changed using a regular expression:
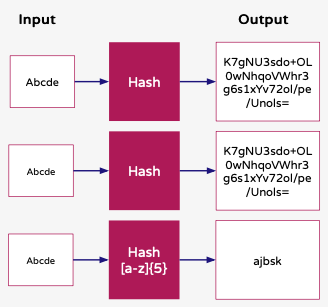
Here are some other examples of regular expressions that could be used to match some example fields and formats:
Field | Format | Expression |
|---|---|---|
Email address | xxxxxxx@xxxxx.com | [a-z]{7}\@[a-z]{5}\.com |
Surname | xxxxxxxx | [a-z]{8} |
Tokenization Behavior
Tokenization Behavior contains various settings that determine how tokenization is performed when the rule is applied to a dataset.
For the Hash text rule, the Behavior setting is fixed as:
Consistency enforced by hashing function but duplicate tokens are possible
This means that the hashing function ensures that the same input value will always return the same output value. But, there is the unlikely possibility of duplicate tokens being generated. (The collision resistance of the SHA256 hashing algorithm is discussed in many external publications.)
However, collisions are much more likely if a regular expression is specified with the rule. For example, if the regular expression defines an output that is smaller than the default hash output.
If Retain NULL values is checked, NULL values in the input will not be replaced or tokenized and will be retained as NULL in the output.