Specifying Input Data Locations (Hive)
The Data Locations section allows the locations of input data to be specified. The Hive tables referenced in this section must conform to the Schema of the Job's Policy.
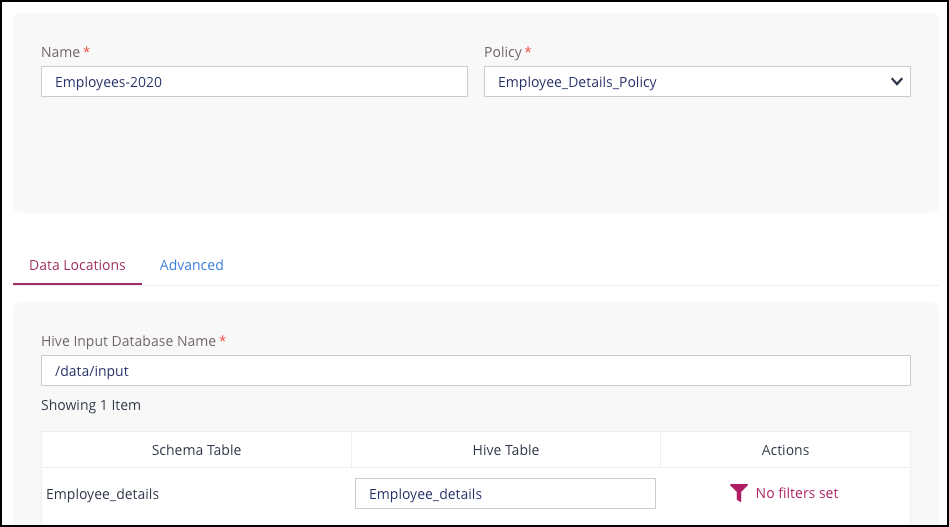
To complete the Data Locations section:
Specify a valid database name in the Hive Input Database Name edit box. All data to be read by the Job must reside in this database as a Job can only be run on one database.
Check that the name of the Hive Table matches the name of the corresponding Schema Table name for the Hive table that you are going to use.
Privitar uses the Schema Table name from the Privitar Schema, but if there is a mis-match, update the Hive Table name to match the table name of the underlying schema. (The table name can be checked by examining the Hive instance using a suitable database analysis tool such as Hue.)
If necessary, apply a filter to the Hive table that you are going to use.
Applying a filter enables a subset of the data in the Hive table to be processed. For more information, see Filtering Hive Data.