
Hadoop Cluster Environment Configuration
A Hadoop Cluster can optionally be added to an Environment.
To add a Hadoop cluster, select the Hadoop Cluster checkbox and click the Configure button to open the Hadoop Cluster configuration dialog box. The dialog box contains six tabs. Each tab has a number of settings that can be used to configure the Hadoop cluster.
Authentication
Spark
Hive
Data Locations
Cluster
Metadata
In addition, a Hadoop Cluster Test button is provided to validate the primary aspects of the configuration.
Authentication
Setting | Description |
|---|---|
Use Kerberos | Enable this option to use a Kerberos keytab to authenticate with a Hadoop cluster. When checked, the following settings are required:
|
Protected Data Domain output paths are managed by Sentry | Enable this option if permissions on Protected Data Domain (PDD) HDFS output paths are managed by Sentry. This prevents Privitar from setting permissions and ownership of PDD output directories and files. PDD output directories must be created and the permissions set outside Privitar. Any user running Jobs must have read/write/execute access on the PDD output directories. |
The Job Authentication section determines the user that Batch Jobs are run as.
In all cases, the user specified is impersonated in the cluster when the Job runs. This relies on appropriate configuration in the cluster to allow impersonation of the user. If specified above, authentication is performed using a Kerberos keytab.
Setting | Description |
|---|---|
Privitar user | Run Jobs as the OS-level user that is running Privitar. If the Job is run in a Kerberized cluster, this is the Kerberos Principal. |
Service user | Specify a list of users that can run Jobs in the cluster. For each user, specify the group that should own the folders and files created when running the Jobs on the cluster. The user specified must belong to the group, or the Jobs will fail to run. The choice of which user to use is made in the Run as user box in the Job itself. |
Spark
The Spark settings specify parameters for submitting Spark jobs used to perform processing in Privitar. The best settings for these parameters are dependent on the specification of the Hadoop cluster and the characteristics of the input data.
The following table provides a basic overview of the available parameters. For more information on tuning, please contact your system administrator.
Setting | Description |
|---|---|
Master | Choose |
Driver Memory (GB) | Heap memory allocated to the Spark Driver. |
Executor Memory (GB) | Heap memory allocated to each of the Spark Executors. |
Executors | Number of Spark Executors requested from YARN when the Job is submitted. |
Executor Cores | Number of cores per Spark Executor requested from YARN when the Job is submitted. |
Memory Overhead (MB) | Amount of additional memory allocated to the Spark Executor in addition to the Executor memory. This memory is allocated on top of the heap memory. |
Allow Jobs to override Spark settings | This setting determines whether individual Jobs that use this Environment can supply their own values for the parameters on this page, overriding the values that are currently displayed in the dialog box. If this check box is enabled, the Spark tab on the Job configuration dialog box can be edited. |
YARN Queue Name | The name of the YARN queue that Spark jobs will be sent to when executing Privitar Jobs configured to use this Environment. If left blank, the setting defaults to no queue. |
Hive
Privitar can read data, write data, and import Schemas from Hive databases in the cluster.
In order to enable this functionality, the hive-site.xml file must be added to the Cluster tab, and the settings on the Hive tab should be reviewed.
A summary of the available settings is provided in the table below:
Setting | Description |
|---|---|
Hive JDBC Connection URL | The JDBC URL for the cluster's Hive installation. This value is used when importing Schemas from Hive databases. During the import process, Privitar connects using JDBC to read Hive table definitions. These definitions are converted to Privitar Schemas. |
Enable Hive Batch Jobs | Select this option to allow the use of Hive Batch Jobs in the Privitar APIs and user interface. This allows users to create and execute Hive Batch Jobs that apply Policies to data stored in Hive databases. |
Thrift URL (read only) | The Thrift URL is automatically determined based on the hive-site.xmlconfiguration added on the Cluster tab. This value is used while executing Hive Batch Jobs to allow Privitar to communicate with the cluster's Hive installation when querying or writing data. |
Warehouse location (read only) | The Warehouse location is automatically determined based on the hive-site.xml configuration added on the Cluster tab. This location is often used by Hive installations as a central location for Hive data. |
Job output root location | When executing Hive Batch Jobs, the HDFS location of output Hive data is controlled by the Job's PDD. This setting determines whether PDDs in this Environment specify the location individually on a per-PDD basis, or whether all PDDs write their data underneath a single location. The choice depends on your organisation's preference for storing Hive table data files. If Allow PDDs to specify their own is selected, then PDDs are individually configured with the location that should be used to hold output Hive table data. This location is specified as part of the PDD creation process. If Specific location is selected, then the single location for all output Hive table data must also be specified. When Hive Batch Jobs are run, table data is written to HDFS in a location formed as follows: Configured location / Database name.db / Table name where the database name is specified in the PDD, and table name is specified in the Hive Batch Job. If desired, this can be set to the Warehouse location that is also displayed on the Hive tab. |
Hive output table type | This setting determines whether Privitar creates internal or external tables when running Hive Batch Jobs. The choice determines the effect on underlying HDFS data if tables are later dropped using Hive. If Internal is specified, dropping the table will also remove the underlying data in HDFS. If External is specified, dropping the table only 'unlinks' the data from Hive, leaving the files on HDFS unchanged. The choice depends on your organisation's preference for storing Hive table data files. For more information about Hive tables, see the Apache Hive documentation. |
Data Locations
The options available for specifying data locations for Hadoop is described in the following table:
Setting | Description |
|---|---|
Lookup Files Path | Location of lookup mappings for the Lookup masking rule. In the Policy configuration for a Lookup rule, a file containing the replacements used by that rule is specified. Lookup Files Path is the base location for such files. |
Report Output Path | Location of internal status files written by Privitar during the execution of a Job. No customer data is stored in these files. |
Dropped Rows Path | When reading CSV data containing malformed rows, Privitar can write a sample of these malformed rows into a location specified here, for debugging purposes. The number of rows written is capped at 100 rows. If no location is specified, no rows are written. |
Cluster
In the Cluster tab, select the cluster type from the Hadoop Cluster Type list box:
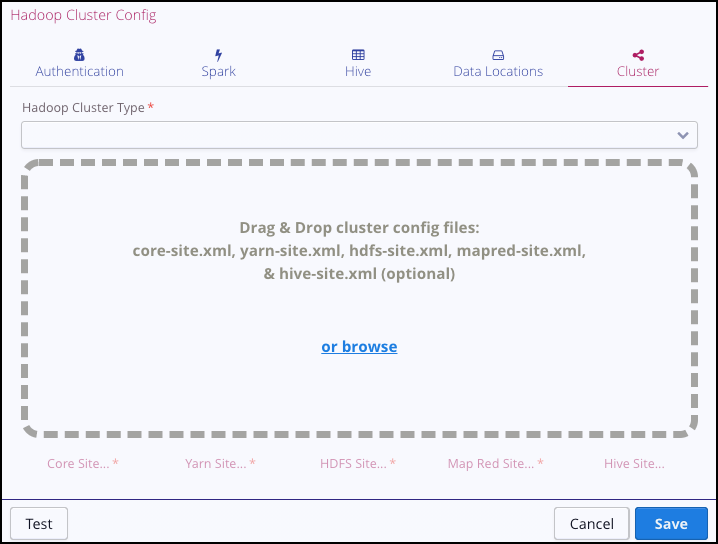
Add the configuration files to the cluster configuration by dragging them onto the dialog box. (The hive-site.xml configuration file is optional.) Typically, the configuration files are provided by a Hadoop administrator.
For more information on creating new Cluster types, see Creating Hadoop Cluster Types.
Hadoop Cluster Test
Hadoop Clusters provide the ability to test themselves, initiated from the Test button on the Environment dialog box and Hadoop Cluster Config dialog box:
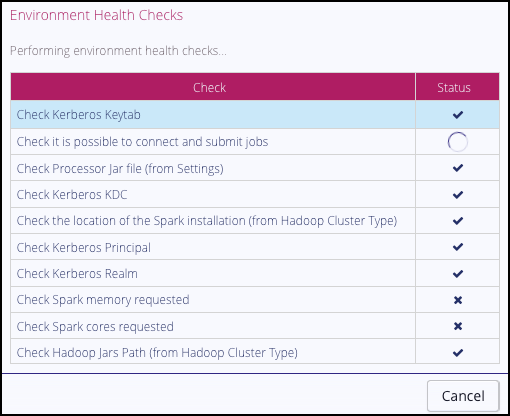
Using this button causes a sequence of checks to be performed on the Privitar platform that verify:
The location of the Privitar .jar file and Spark binaries are correctly specified in the Settings dialog box.
That it is possible for the Privitar application to connect to the Hadoop cluster and successfully submit processing jobs.
That the Environment is able to successfully allocate the cores and memory requested on the Spark tab.
If any of these checks fail, a debugging message is displayed in the dialog box.