What is a Token Vault?
A Token Vault is a secure storage mechanism for tokens generated during de-identification. Each Token Vault is associated with a single Protected Data Domain.
When a Job requiring consistent tokenization is run, the PDD's Token Vault is populated with a mapping from the original source values to the tokens produced as replacements. Then, when multiple columns across different tables are masked with Rules with the Preserve data consistency option enabled, the same Token Vault - and hence the same mapping - is used to transform values across all the tables.
This is important because it means that the same tokenized value will be produced in both output tables for the same input value. In this way joining relationships based on values in those columns are preserved.
Consider the following dataset of users containing three fields; ID, Name and Country:
ID | Name | Country |
|---|---|---|
12345 | John Doe | US |
73847 | Jane Smith | UK |
82375 | Sally Jones | US |
The columns in the dataset are tokenized using the Regular Expression Text Generator rule with the Preserve data consistency option enabled. The following table defines the regular expression rule that is applied to each column:
ID | Name | Country |
|---|---|---|
|
|
|
After applying the rules to the dataset, the de-identified dataset (in the Protected Data Domain) could be transformed as shown in the following table:
ID | Name | Country |
|---|---|---|
23421 | akAsdLn | YjqD |
53627 | yTbqnKas | QwRg |
93464 | obAsOias | YjqD |
Note
As consistent tokenization has been used, the two entries for US have been tokenized with the same value (YjqD).
The same Token Vault is reused across successive runs of any Job targeting the same PDD. This means that if new data or different datasets are published to the PDD, any values that have already been tokenized in previous runs will be mapped to the existing tokens. This allows consistency to be maintained over time.
After a Token Vault has been populated by running a Job, it is possible to retrieve the original value for a token, provided the token itself is known and certain security requirements are met.
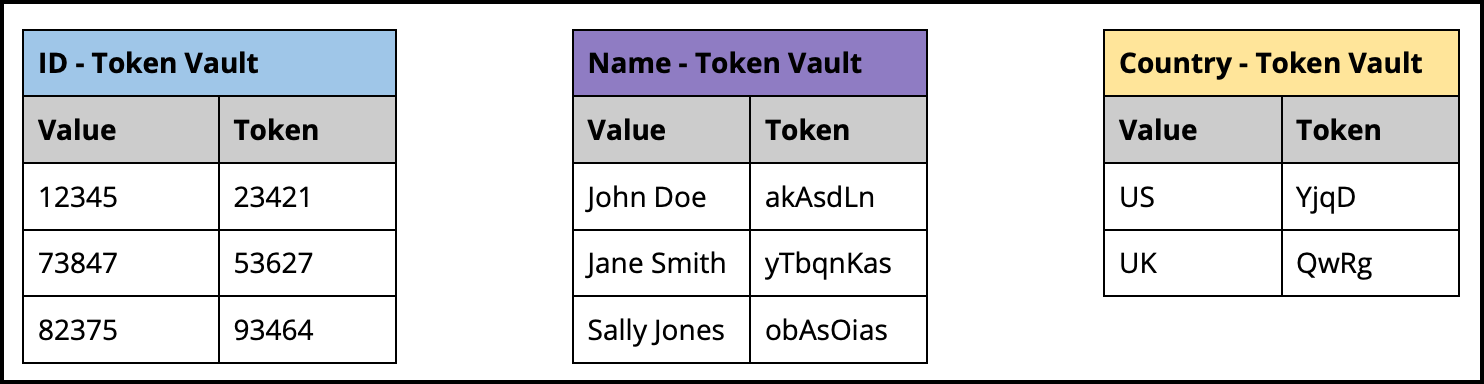
In order to be able to reveal (unmask) the mappings between the de-identified dataset and original dataset, the relationships are maintained by storing the mappings in the Token Vault. The Token Vault has a table, per rule, to store these mappings.
In the example above - which uses three rules - there are three tables in the token vault: ID, Name and Country.
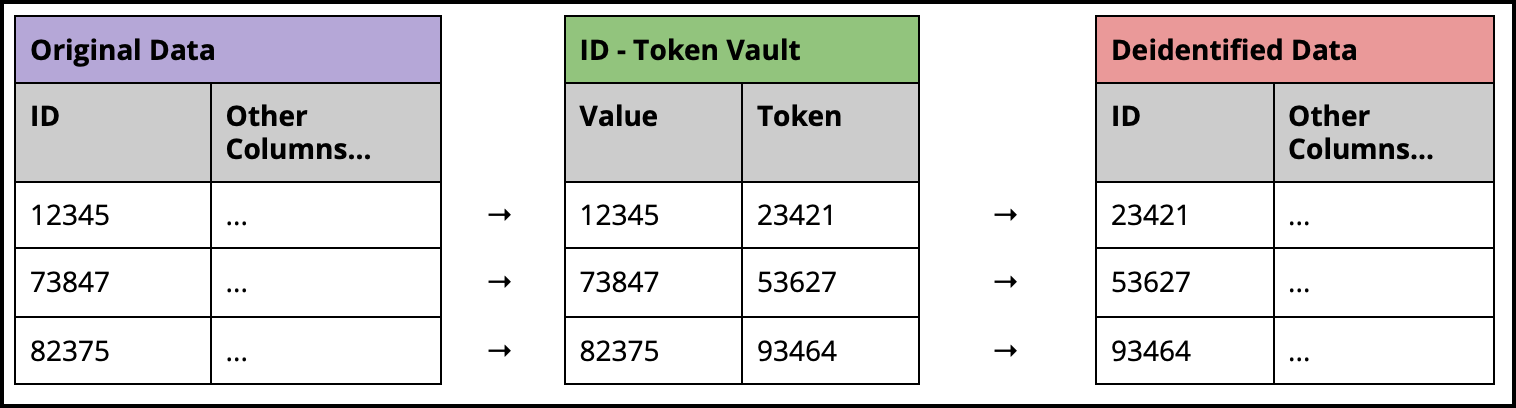
For the ID values, the de-identification flow from original values to the de-identified data is shown in the following diagram:
For more information about finding the original values of de-identified data, see Unmasking De-identified Data.