Specifying Input Data Locations (HDFS and Cloud Storage)
The Data Locations section enables the locations of input data to be specified. The data items referenced in this section must conform to the Schema of the Job's Policy.
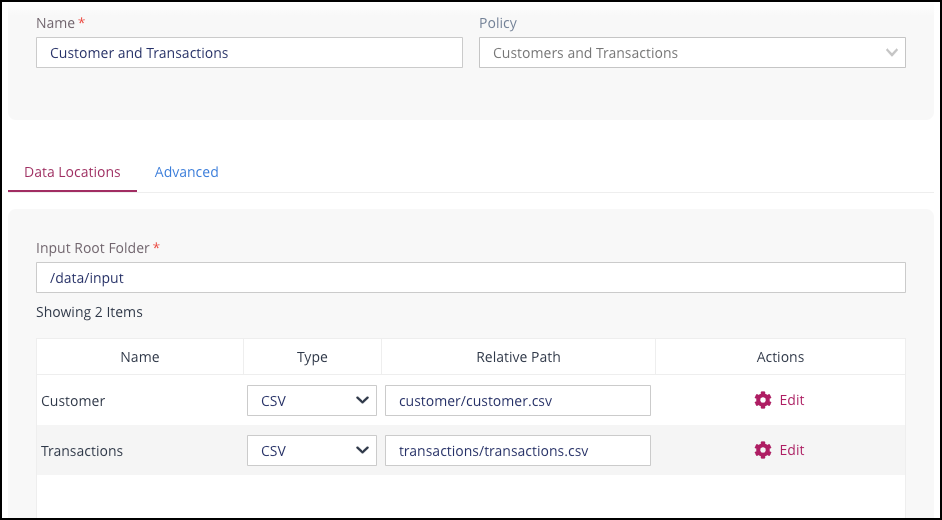
To complete the Data Locations section:
Specify a valid pathname in the Input Root Folder box. All files to be read by the Job must reside under this location.
For each table displayed, specify the following:
Type of file in the Type column. This can be one of CSV, Avro or Parquet.
The path to the table in the Relative Path box.
The files representing the input are referred to using a path that is matched relative to the folder specified in the Input Root Folder box, and may represent either a single file, or multiple files if wildcards are used. For more information about Relative Paths, see Partitioned Data and Wildcards (HDFS).
If the selected input type is CSV or Avro, additional Settings for these file types can be configured by clicking on the Cog icon in the Settings column.
Reading from Cloud Storage
When using Privitar in a Cloud Environment, native Cloud storage platforms can be directly used to read and write data with Batch Jobs. This is configured from the Data Locations section of the Batch Job.
The following table defines the syntax to use when specifying a data location for the Cloud storage platforms that are supported by Privitar.
Compute Platform | Container | Location syntax |
|---|---|---|
Amazon EMR Cluster | S3 |
|
AWS Glue | S3 |
|
Azure HDInsight | Blob |
|
Google Dataproc | Bucket | Prefix path with: |
BlueData | DataTap | Prefix path with: |