Custom directory structure of initial load output files on Amazon S3, Google Cloud Storage, and ADLS Gen2 targets
Custom directory structure of initial load output files on Amazon S3, Google Cloud Storage, and ADLS Gen2 targets
You can configure a custom directory structure for the output data files that initial load jobs write to Amazon S3, Google Cloud Storage, and Microsoft Azure Data Lake Storage (ADLS) Gen2 targets if you do not want to use the default structure.
By default, initial load jobs write output files to
tablename
_
timestamp
subdirectories under the parent directory. For all targets except Google Cloud Storage, the parent directory is specified in the target connection properties if the
Connection Directory as Parent
check box is selected on the
Target
page of the task wizard. In an Amazon S3 connection, this parent directory is specified in the
Folder Path
field. In an ADLS Gen2 connection, the parent directory is specified in the
Directory Path
field. For Google Cloud Storage targets, the parent directory is the bucket container specified in the
Bucket
field on the
Target
page of the task wizard.
You can customize the directory structure to suit your needs. For example, you can write the output files under a root directory or directory path that is different from the parent directory specified in the connection properties to better organize the files for your environment or to find them more easily. Or you can consolidate all output files for an object directly in a directory with the object name rather than write the files to separate timestamped subdirectories, for example, to facilitate automated processing of all of the files.
To configure a directory structure, you must use the
Data Directory
field on the
Target
page of the ingestion task wizard. The default value is
{TableName}_{Timestamp}
, which causes output files to be written to
tablename
_
timestamp
subdirectories under the parent directory. You can configure a custom directory path by creating a directory pattern that consists of any combination of case-insensitive placeholders and directory names. The placeholders are:
{TableName} for a target table name
{Timestamp} for the date and time, in the format yyyymmdd_hhmissms, at which the initial load job started to transfer data to the target
{Schema} for the target schema name
{YY} for a two-digit year
{YYYY} for a four-digit year
{MM} for a two-digit month value
{DD} for a two-digit day in the month
A pattern can also include the following functions:
toLower() to use lowercase for the values represented by the placeholder in parentheses
toUpper() to use uppercase for the values represented by the placeholder in parentheses
By default, the target schema is also written to the data directory. If you want to use a different directory for the schema, you can define a directory pattern in the
Schema Directory
field.
Example 1
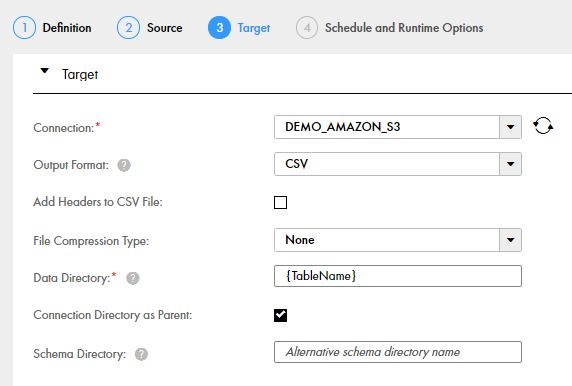
You are using an Amazon S3 target and want to write output files and the target schema to the same directory, which is under the parent directory specified in the
Folder Path
field of the connection properties. In this case, the parent directory is idr-test/DEMO. You want write all of the output files for an object to a directory that has a name matching the table name, without a timestamp. You must complete the
Data DIrectory
field and select the
Connection Directory as Parent
check box. The following image shows this configuration on the
Target
page of the task wizard:
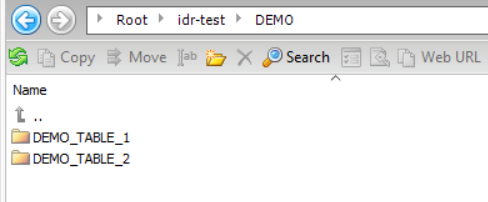
Based on this configuration, the resulting directory structure is:
Example 2
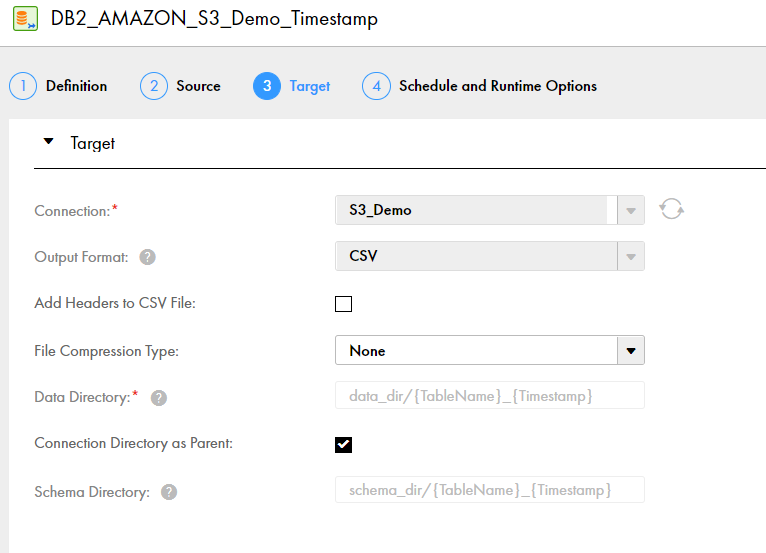
You are using an Amazon S3 target and want to write output data files to a custom directory path and write the target schema to a separate directory path. To use the directory specified in the
Folder Path
field in the Amazon S3 connection properties as the parent directory for the data directory and schema directory, select
Connection Directory as Parent
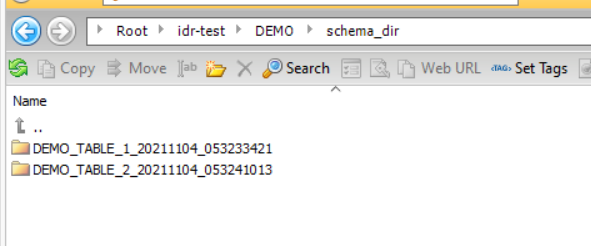
. In this case, the parent directory is
idr-test/DEMO
. In the
Data Directory
and
Schema Directory
fields, define directory patterns by using a specific directory name, such as data_dir and schema_dir, followed by the default {TableName}_{Timestamp} placeholder value. The placeholder creates
tablename
_
timestamp
destination directories. The following image shows this configuration on the
Target
page of the task wizard:
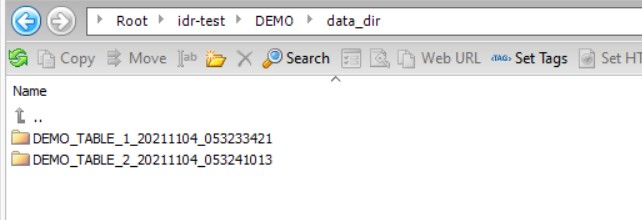
Based on this configuration, the resulting data directory structure is:
 ASK INFAPreview
ASK INFAPreview