Data Engineering Integration
- Data Engineering Integration H2L
- All Products

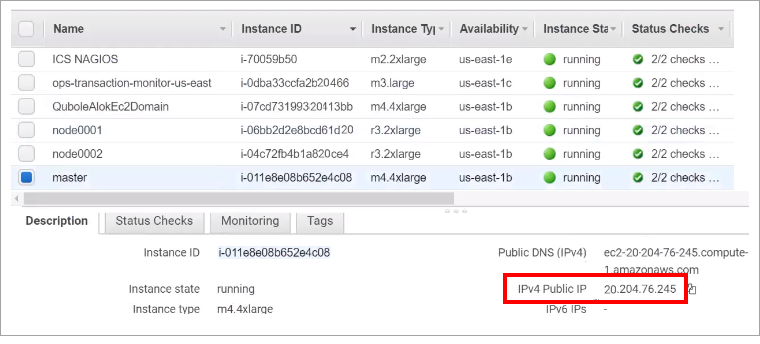
<property> <name>hive.metastore.uris</name> <value>thrift://<fully qualified master host name>:10000</value> <description>JDBC connect string for a JDBC metastore</description> </property>
