Configuration
This section describes how to use the Privitar StreamSets data processor in a StreamSets pipeline for Data Flow Masking Jobs.
A pipeline consists of stages that represent the origin and destination of the pipeline, and any additional processing that you want to perform. The Privitar StreamSets data processor can be included in between these two stages and is fully compatible with all the different types of components that can be used in each stage of the processing pipeline.
The example pipeline described in this section is a simple pipeline that is used for example only. In this example, data is processed from an input directory, de-identified by the platform processor and written out to an output directory. The setup is shown in StreamSets below:
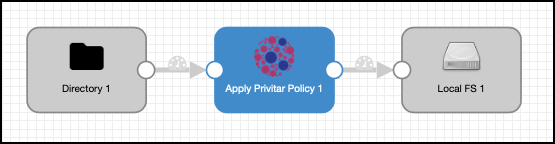 |
To create this example pipeline from StreamSets, you need to create a Data Flow job in the platform and then construct a pipeline in StreamSets that will use the platform processor to de-identify the data.
Note
In this example, StreamSets connects to the platform using Basic authentication, which requires the creation of an API user that has the authorization rights to run Data Flow jobs. For more information about configuring users in the platform to run Data Flow Jobs, refer to Configuring users.
Configuration procedure
To configure the platform processor, follow the procedure below:
Create a Data Flow job in the platform.
Record details about the Data Flow job required by StreamSets.
Create a StreamSets Data Pipeline.
Configure the Origin and Destination components.
Configure the Privitar Processor.
Create a Data Flow job in the platform
To create a Data Flow job in the platform, refer to the Privitar Data Privacy Platform User Guide for general instructions about creating a Data Flow job. Creating a job involves creating a Schema, creating a Policy of rules that will be applied to the data in the Schema and finally defining a Data Flow job to process the data.
When creating the Schema, it is important to ensure that the StreamSets data types defined in the Schema are supported by the platform processor. The processor will map StreamSets data types to platform data types and this may cause errors at the processing stage if the defined Privitar Schema does not match the data types of the underlying input file. For more information about the mapping of data types between StreamSets and the platform, refer to Supported Data Types.
Record details about the Data Flow job
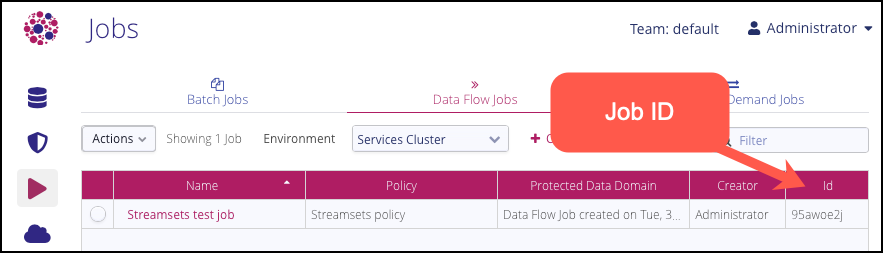
You will need the following details from the platform when setting up the StreamSets pipeline:
The Job ID for the Data Flow job created in the platform. See:
Create a StreamSets Data Pipeline
To create a StreamSets pipeline that uses the platform processor:
Create a a new pipeline by selecting, Create New Pipeline from the StreamSets Pipelines page.
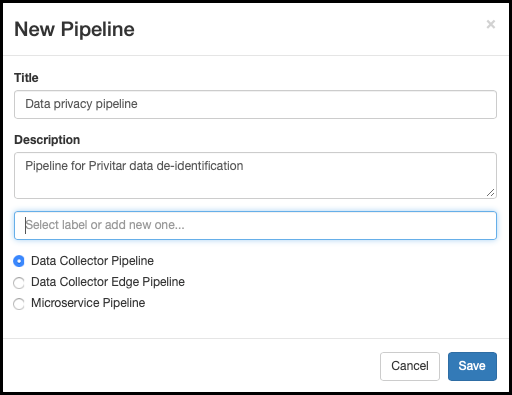
Enter the details for the new pipeline in the New Pipeline dialog box.
Select Data Collector Pipeline as the pipeline type:
Select a data source (Origin) from the Select Origin drop-down list box. Choose, Directory.
Select a data processor to connect to from the Select Processor to connect … list box. Choose, Apply Privitar Policy from the drop-down list box.
Select a data target (Destination) from the Select Destination to connect … list box. Choose, Local FS.
Configure the Origin and Destination Components
For information on how to configure the Origin and Destination components, refer to the StreamSets documentation.
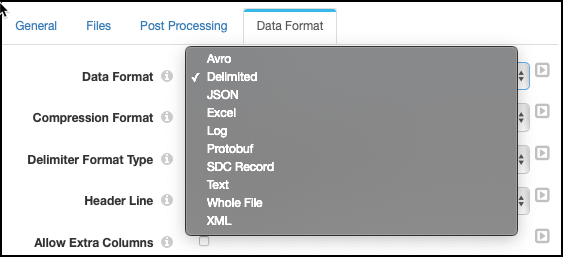
Note that when configuring the Origin component you need to check that the data format of the files to be processed are supported:
The Privitar StreamSets data processor has been specifically tested with JSON, Avro and Delimited file formats, but can process many other file formats.
Refer to the StreamSets documentation (Data Formats Overview) for more information about supported file formats.
The file format used in the Origin data source is defined in the Data Format tab:
 |
Configure the Privacy Platform Processor
To configure the platform processor, you need to edit the Authentication tab and the Data Flow tab with details about the Data Flow job you have setup on the platform, together with connection details to use to connect from StreamSets to the platform.
Edit the Authentication tab to define how StreamSets connects to the platform:
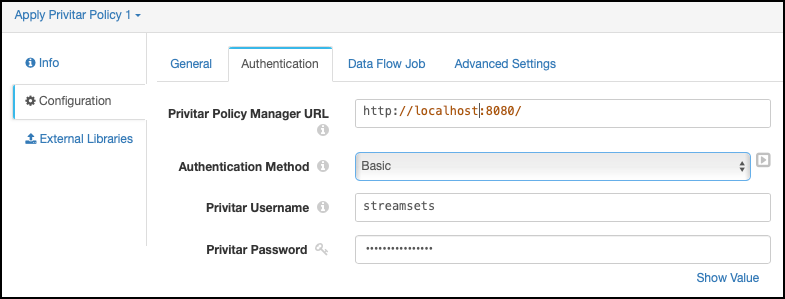
Enter the http address and port number for the platform. For example:
http://localhost:8080.If you are using Basic Authentication, the address and port number must be of the format:
http://<address>:8080If you are using Mutual TLS authentication, the address and port number must be of the format:
https://<address>:8443Select the authentication method from the Authentication Method drop-down list box, depending on the authentication method used to connect to the platform:
For Basic Authentication and Mutual TLS Authentication, enter the Privitar username and Privitar password details for an existing API user on the platform that has a Role with a Run Data Flow permission in the Team that the Data Flow Job is defined in.
Additionally, for Mutual TLS authentication, enter the necessary certificate and password information.
In the Data Flow Job tab, enter the Job ID of the Data Flow job that you want to run in this pipeline.
It’s worth noting that you can only use one Job ID per StreamSets processor. It is not possible to run multiple Job IDs in a processor. The Job ID you specify when setting up the processor is the only job that can be run by that processor. If you want the processor to run a different job, you need to enter a new Job ID in this tab, or create a new data pipeline.
Select Start to run the pipeline. If there are no errors, the activity of the data processing pipeline will be displayed in the Summary window showing the data records being processed.
For more information about all the configuration options that are available for the platform processor, refer to Configuration Options.
Usage and Setup for Data Flow UnMasking Jobs
The usage and setup of the platform data processor in a StreamSets pipeline for Data Flow UnMasking Jobs is very similar to the requirements for a Data Flow Masking Job. Here are some differences to be aware of:
Need to ensure that if you have created an API User for connecting to the platform from Streamsets that this user also has rights to Run Data Flow for Unmasking jobs. In the default Team in the platform this permission is not enabled. For more information, see Configuring users.