Architecture
A simplified architectural diagram showing how the Privitar StreamSets Processor interfaces to the Privitar Policy Manager and Token Vault is shown below:
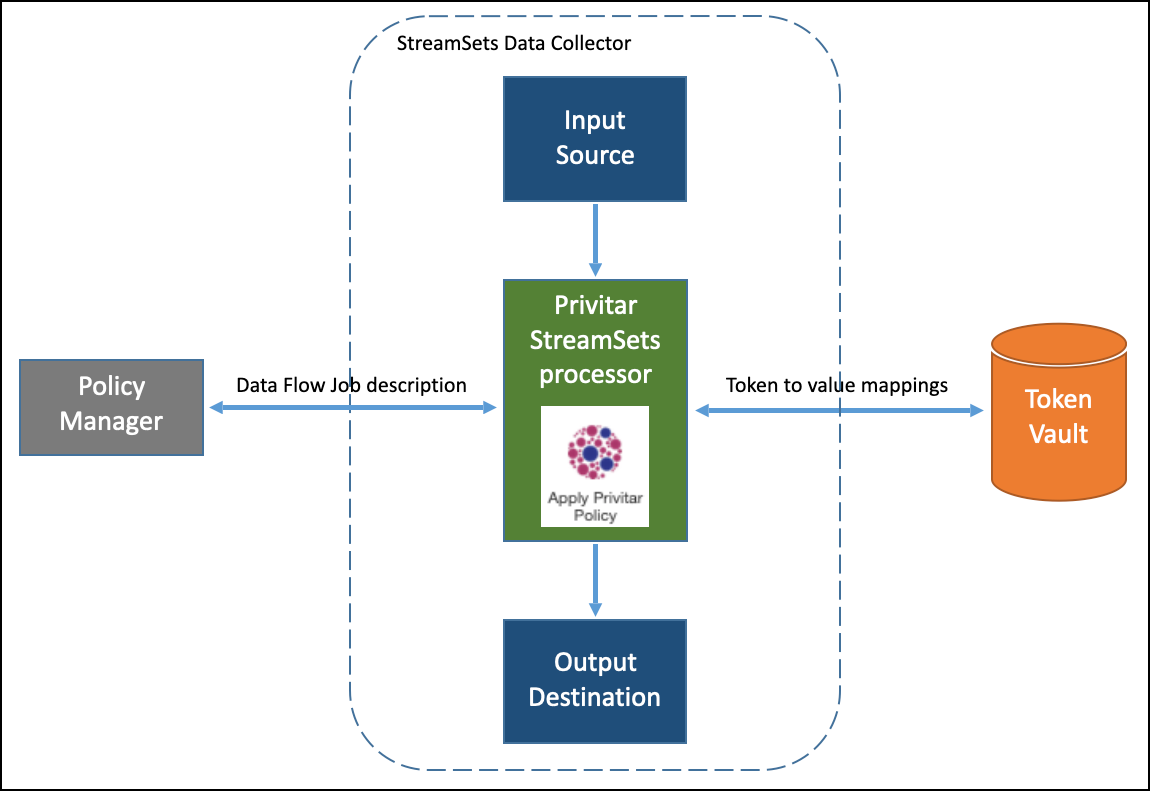 |
The process for de-identifying data in StreamSets using the Privitar StreamSets data processor (Apply Privitar Policy) is:
A data pipeline setup is initiated from the StreamSets Data Collector.
The data from the StreamSets Input source (Origin) is fed to the Privitar StreamSets processor.
The Privitar StreamSets processor contacts the Privitar Policy Manager for details about the Data Flow job that StreamSets has configured the processor to run on the input data.
The Privitar StreamSets processor applies the Data Flow Job details (Policy, PDD descriptions, Token Vault locations) on the input data to de-identify the data.
If the Data Flow Job uses a Policy that is configured to use Consistent Tokenization for certain rules, it will connect to the configured Token Vault to read/write tokens. (To improve performance, a local in-memory cache is used by the Privitar StreamSets processor.)
The Processed data is written out by the Privitar processor to a PDD in the Output destination (Destination).
The process for re-identifying (UnMasking) data in StreamSets using the Privitar StreamSets processor (Apply Privitar Unmasking) is the same. In this case the Input source would be a Privitar PDD.